8. 过拟合
复杂的模型将训练数据的抽样误差考虑在内,对抽样误差也进行了拟合。过拟合的模型可以看成是完全记忆型模型。
8.1. 表现
训练误差小,测试误差大,泛化能力差。
8.2. 原因
训练集大小与模型复杂度不匹配;
样本的噪声太大甚至掩盖了真实样本的分布规律;
训练迭代次数太多(Over-Training)。
8.3. 解决方案
调小模型复杂度
Data Augmentation
- Dropout
Dropout 随机屏蔽了部分神经元的前向和反向传播,有利于保持神经元的独立性;由于每次迭代都屏蔽不同神经元,因此模型的训练过程可以看作是多个模型的集成。
- Early Stopping
记录观察 Validation Accuracy,及时停止训练。
- 集成学习
Bagging:并行化模型生成,减小模型 Variance。
Boosting:串行化模型生成,减小模型 Bias。
- 正则化
L0 正则化(非 0 元素个数),难以优化求解(NP-Hard)。
L1正则化(元素绝对值之和, Lasso Regression),是 L0 范数的最优凸近似,使权值稀疏。权值稀疏的好处:特征选择 && 可解释性。
L2正则化(元素平方和,Ridge Regression / Weight Dacay),使权值分布均匀且值较小。
8.4. Dropout 的 numpy 实现
前向传播:生成 mask,乘以当前层的激活函数输出。新的输出需要除以 keep_prob,保证能量一致。
反向传播:也要关闭 mask 对应的神经元,同样也需要除以 keep_prob。
\(\color{darkgreen}{Code}\)
1def forward_propagation_with_dropout(X, parameters, keep_prob = 0.5):
2
3 """
4
5 Implements the forward propagation: LINEAR -> RELU + DROPOUT -> LINEAR -> SIGMOID.
6
7 Arguments:
8
9 X -- input dataset, of shape (2, number of examples)
10
11 parameters -- python dictionary containing your parameters "W1", "b1", "W2", "b2":
12
13 W1 -- weight matrix of shape (20, 2)
14
15 b1 -- bias vector of shape (20, 1)
16
17 W2 -- weight matrix of shape (1, 20)
18
19 b2 -- bias vector of shape (1, 1)
20
21 keep_prob - probability of keeping a neuron active during drop-out, scalar
22
23 Returns:
24
25 A2 -- last activation value, output of the forward propagation, of shape (1,1)
26
27 cache -- tuple, information stored for computing the backward propagation
28
29 """
30
31 np.random.seed(1)
32
33 # retrieve parameters
34
35 W1 = parameters["W1"]
36
37 b1 = parameters["b1"]
38
39 W2 = parameters["W2"]
40
41 b2 = parameters["b2"]
42
43
44 # LINEAR -> RELU -> LINEAR -> SIGMOID
45 # Z1 = W1 x X + b1, A1 = relu(Z1), A1 = dropout(A1)
46 # Z2 = W2 x A1 + b2, A2 = sigmoid(Z2)
47
48 Z1 = np.dot(W1, X) + b1
49
50 A1 = relu(Z1)
51
52 # 4 steps
53
54 D1 = np.random.rand(Z1.shape[0], Z1.shape[1]) # Step 1: initialize matrix D1 = np.random.rand(..., ...)
55
56 D1 = D1 < keep_prob # Step 2: convert entries of D1 to 0 or 1 (using keep_prob as the threshold)
57
58 A1 = A1 * D1 # Step 3: shut down some neurons of A1
59
60 A1 = A1 / keep_prob # Step 4: scale the value of neurons that haven't been shut down
61
62 Z2 = np.dot(W2, A1) + b2
63
64 A2 = sigmoid(Z2)
65
66 cache = (Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2)
67
68 return A3, cache
1def backward_propagation_with_dropout(X, Y, cache, keep_prob):
2
3 """
4
5 Implements the backward propagation of our baseline model to which we added dropout.
6
7 Arguments:
8
9 X -- input dataset, of shape (2, number of examples)
10
11 Y -- "true" labels vector, of shape (output size, number of examples)
12
13 cache -- cache output from forward_propagation_with_dropout()
14
15 keep_prob - probability of keeping a neuron active during drop-out, scalar
16
17
18 Returns:
19
20 gradients -- A dictionary with the gradients with respect to each parameter, activation and pre-activation variables
21
22 """
23
24 m = X.shape[1]
25
26 (Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2) = cache
27
28
29 dZ2 = A2 - Y # logistic regression
30
31 dW2 = 1./m * np.dot(dZ2, A1.T) # logistic regression
32
33 db2 = 1./m * np.sum(dZ2, axis=1, keepdims = True)
34
35
36 dA1 = np.dot(W2.T, dZ2)
37
38 dA1 = D1 * dA1 # Step 1: Apply mask D1 to shut down the same neurons as during the forward propagation
39
40 dA1 = dA1 / keep_prob # Step 2: Scale the value of neurons that haven't been shut down
41
42 dZ1 = np.multiply(dA1, np.int64(A1 > 0)) # Hadamard product, i.e., element-wise product
43
44 dW1 = 1./m * np.dot(dZ1, X.T)
45
46 db1 = 1./m * np.sum(dZ1, axis=1, keepdims = True)
47
48
49 gradients = {
50 "dA2": dA2, "dZ2": dZ2, "dW2": dW2, "db2": db2,
51 "dA1": dA1, "dZ1": dZ1, "dW1": dW1, "db1": db1
52 }
53
54 return gradients
8.5. 附:正则化
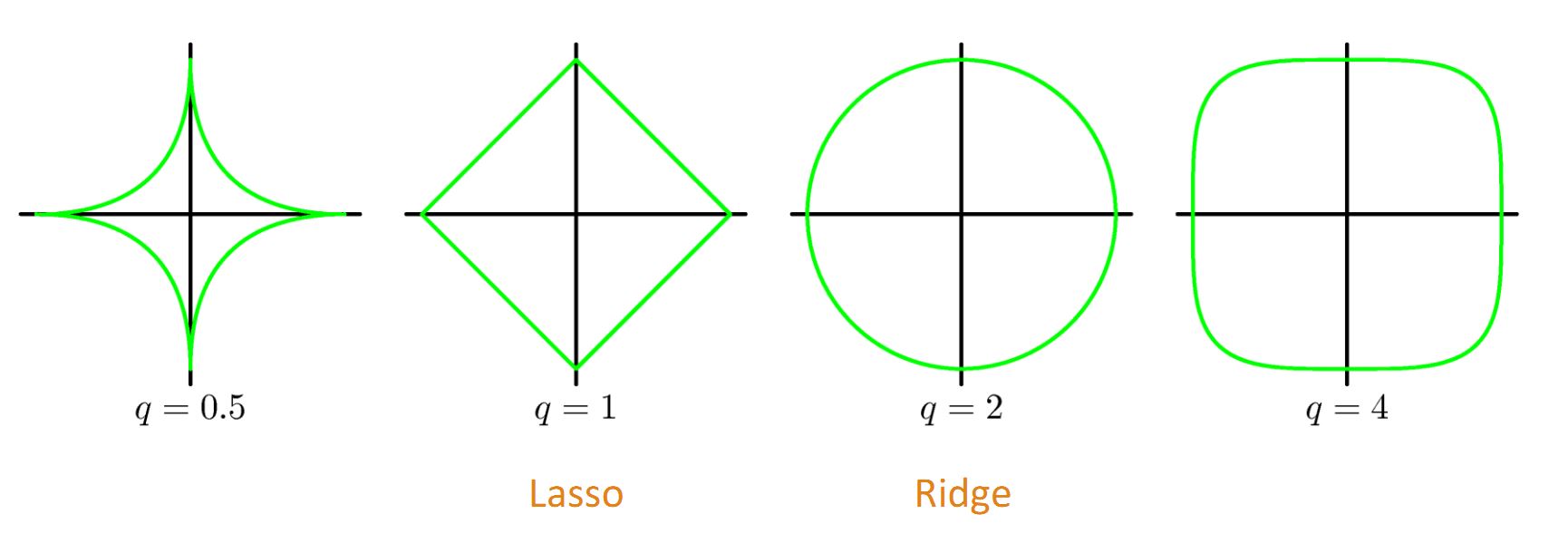
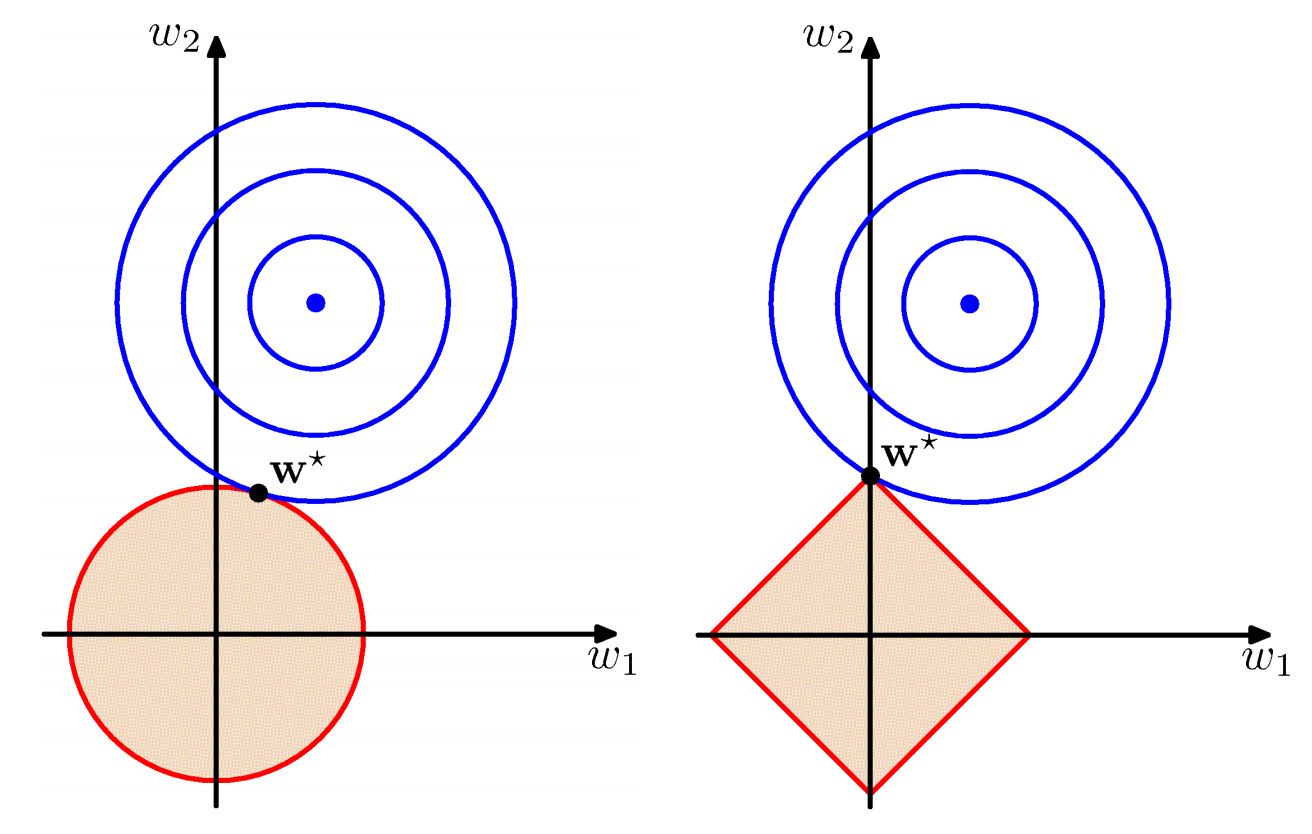
我们通常只对权重(Weight)做正则惩罚,而不对偏置(Bias)做正则惩罚。精确拟合偏置所需的数据通常比拟合权重少得多。每个权重会指定两个变量(前层-后层) 如何相互作用,我们需要在各种条件下观察这两个变量才能良好地拟合权重;而每个偏置仅控制一个单变量(后层),这意味着:即使不对其进行正则化也不会导致太大的方差。 另外,对偏置进行正则化可能导致明显的欠拟合。
- No Free Lunch Theorem
没有一个机器学习算法总是比其他算法好。这意味着机器学习研究不是要找一个通用的学习算法或是最好的学习算法,而是理解 什么样的分布与人工智能获取的经验分布相关,以及什么样的学习算法在我们关注的数据分布上效果更好。
- Occam’s Razor
如果关于同一个问题有许多种理论,每一种都能作出同样准确的预言,那么应该挑选其中使用假定最少的。尽管越复杂的方法通常能做出越好的预言,但是在不考虑预言能力(即结果大致相同)的情况下,假设越少越好。
8.6. 参考资料
深度学习(Deep Learning)基础概念8:L2正则化(L2 Regularization)、Dropout原理及其python实现